
五大计算平台竞逐高阶自动驾驶量产,谁是最强芯片?



自动驾驶系统前装量产的开发周期大约 2 到 3 年,因此计算平台厂家都是提前 2 到 3 年提供芯片样片。
整个系统开发完成后,芯片才开始量产。
这样一来,实际上 2023 年后的自动驾驶芯片格局,今天就已经基本确定了。
自动驾驶芯片开发成本高昂,且出于对高性能、低功耗的要求,其制造至少需要 7 纳米和 5 纳米的制程工艺。
这个级别的工艺对出货量要求比较高:
一方面因为台积电几乎垄断 7 纳米以下的高性能芯片代工,产能紧缺。
订单量太低的话,芯片厂商将在台积电的序列中等待排期。
这个排期长达 1 年半到 3 年。
在这个时间内,芯片厂商肯定会失去客户。
另一方面,7 纳米以下芯片的开发成本高昂,动辄 10 亿美元起。
如果没有足够多的出货量摊销,芯片单价会很高,反过来也会影响销售。
在现在市场的主要玩家中,特斯拉和苹果的系统封闭软硬一体化,不对外单独出售芯片。
华为提供 MDC 计算平台,但其芯片也不对外单独出售。
当前,能够提供高性能自动驾驶芯片,并在市场中拥有一席之地的全球独立芯片厂商主要还有:Mobileye、英伟达、瑞萨、高通。
其对应的芯片产品如下:
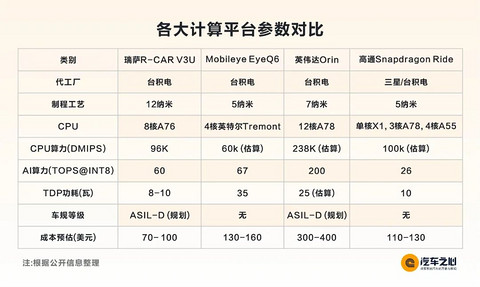
因为这些芯片涉及到多个版本,这里对比的都是顶配产品。
1、Mobileye EyeQ6,拥抱英特尔,追逐高性能
2019 年底,Mobileye EyeQ 芯片全球累计出货超过 5400 万片。
2020 年 9 月,Mobileye 透露,EyeQ 芯片全球出货量超过 6000 万片。
这 6000 万片是 EyeQ2、EyeQ3 和 EyeQ4 之和,其中 2020 年新增的部分主要是 EyeQ4。
目前 EyeQ5 还未批量出货。
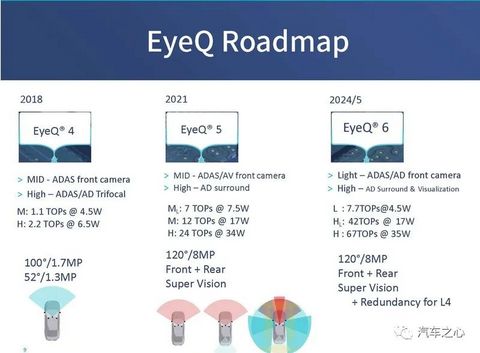
EyeQ5 提供的算力水平是最高 24 TOPS,跟其他几家相比,这个算力水平要逊色不少。
EyeQ6 才是 Mobileye 真正发力高性能的高端。
EyeQ6 预计于 2024/2025 年量产,分为高中低三个版本。
Mobileye 在 2016 年开始设计 EyeQ5,选定了 MIPS 的 I6500 做架构。
MIPS 在 I6500 架构之上,推出了特别针对车规的 I6500-F,而后续的 I7200 是针对无线市场的。
因此,Mobileye 在之后的一代芯片上,放弃了 MIPS 架构,而决定采用英特尔的 Atom 内核[1]。
Atom 是英特尔处理器系列的常青树,典型车载平台是 Apollo Lake。
2016 年 6 月,英特尔从 Apolllo Lake 切换到 Goldmont 架构,并先后在特斯拉、宝马、卡迪拉克、红旗、现代、沃尔沃、奇瑞的车机上大量使用。
其中宝马采用的最多,几乎全系列都是。
特斯拉 Model 3 也是用的 Apolllo Lake。
最新的 Atom 系列,是 2020 年 9 月推出的 Elkhart Lake 系列即 x6000E,使用 Tremont 架构。
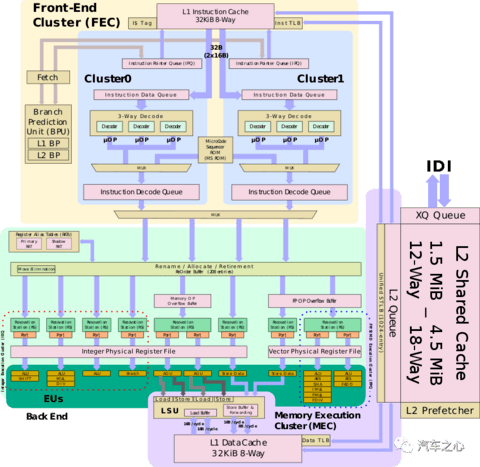
相比上代架构,Tremont 架构主要增加了 L2 cache,工艺从 14 纳米提升到 10 纳米,运行频率略微提高约 200MHz,最高睿频可达 3.0GHz。
和上一代一样,Tremont 架构最多也是4核。
整体上,Mobileye 的芯片更新速度较慢。
加上最近英特尔的 CPU 核心业务受到来自苹果、微软和 AMD 的打击,公司市值下滑明显。
EyeQ6 要到 2024 年才量产,在各家的竞争中也显得有些落后了。
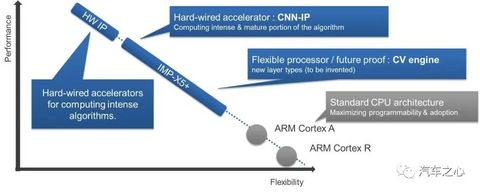
2、瑞萨 R-CAR V3U,强势日系厂商,灵活高性价比
瑞萨是全球第二大汽车半导体厂家,全球第一大汽车 MCU 厂家,也是日本除索尼(索尼的主营业务主要是图像传感器)外最大的半导体厂家。
在高性能车载计算方面,瑞萨目前最顶级的产品是R-CAR H3,主要用在座舱领域。
最初 R-CAR H3 也考虑了自动驾驶应用,但 R-CAR H3 设计时间是 2013 年。
很难预料到今天客户对AI算力和 CPU 算力的需求这么强。
R-CAR H3 没有内置 AI 加速器,CPU 算力也只有 40K,显然达不到自动驾驶系统开发的要求。
目前主要被用在座舱量产中,比如 2021 款长城 H6。还有 R-CAR M3 被用于大众中国车型的座舱上。
瑞萨在 2017 年开始加强高算力芯片的设计。
2019年推出第一个视觉 SoC,即R-CAR V3H。
这颗芯片的 AI 算力有 4 TOPS,博世的下一代视觉系统内嵌 V3H,也包括一些日系的全自动泊车系统。
2018 年,瑞萨开始设计 V3H 的加强版 V3U,到 2020 年基本完成设计。
目前外部已经可以申请 V3U 的样片,这个速度比其他三家都要快一些。
V3U 的量产预计在2023 年初,丰田和本田也参与了这款芯片的设计工作。
日本车企和供应商之间的抱团非常紧密,我认为丰田和本田自动驾驶系统大概率会采用 V3U。
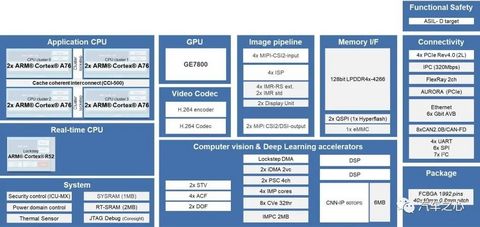
V3U 内部框架如上图:采用 8 核 A76 设计。
瑞萨没有像特斯拉一样,堆了 12 个 A72,而是使用了 ARM 的 Corelink CCI-500,即 Cache 一致性互联。
V3U 的视频处理管线如上图,可以看到 V3U 有很多硬核的计算机视觉模块,包括立体双目视差,稠密光流、CNN、DOF、STV、ACF 等。
在计算机视觉功能方面,支持包括图像格式化、目标追踪、车道检测、自由空间深度、场景标注、语义分割、检测分类等模块。
为了节约成本,降低功耗,同时也聚焦于车载应用需求,瑞萨没有使用太昂贵的 GPU,只是增加了一个低功耗 GPU,即:
Imagination Technologies 的 PowerVR GE7400,1 个着色器集群+ 32 个 ALU核心,算力只有38.4 GFLOPS@600MHz。
考虑到成本因素,瑞萨没有使用时髦的 7 纳米,而是12 纳米工艺,并且是从原瑞萨 R-CAR H3 的 16 纳米 FinFET 工艺升级到 12 纳米 FFC 工艺,一次性支出很少。
但是论到 AI 性能,丝毫不次于那些 5 纳米芯片,瑞萨声称 V3U 达到了惊人的 13.8 TOPS/W 的能效比,是顶配 EyeQ6 的 6 倍之多[2]。
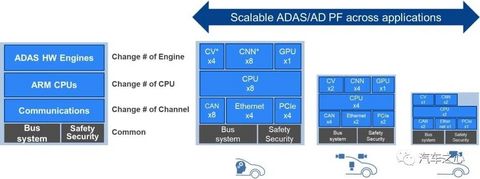
V3U 也是一个系列产品,针对不同层级自动驾驶的需求可以提供多个版本,这样做是为了进一步提高出货量,降低成本。
V3U 的产品系列采用的是模块化设计,A76 可以是 2、4、8 核。
GPU 也可以不要,外设也可以轻松增减,灵活性很强。
在 Mobileye、瑞萨、英伟达、高通四大自动驾驶芯片厂家中,只有瑞萨的主业是汽车半导体,因此对车规安全重视程度最高,V3U 的规划目标是ASIL-D。
3、英伟达 Orin:极致性能,新造车青睐
英伟达于 2019 年底发布了 Orin 芯片:
预计在 2022 年或 2023 年量产,2021 年初有样片提供。
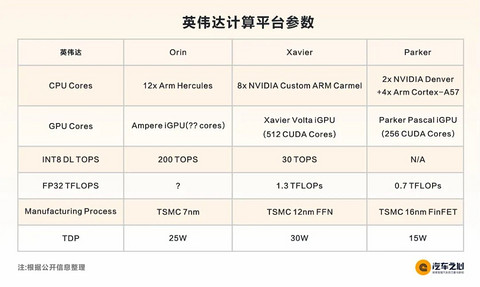
关于 Orin 的公开资料一直还停留在 2019 年底发布时。
据说围绕 Orin 的软件工作异常复杂,硬件已经完全就绪,可能要到 2023 年底才能量产。
Orin 性能一流,但价格可能非常昂贵。
L4 级自动驾驶,自然也是非常昂贵的。主芯片上降低几百美元,对上万美元的系统来说也是杯水车薪。
大部分厂家在 L4 的投入上,都是为了树立旗帜,制造高科技形象。
大规模量产难度很高,配套的 V2X、高精度地图和高精度定位都很不成熟,法规也需要修改。
因此,开发初期厂商对成本不敏感。换句话说,车厂没指望在主芯片上降低成本。

与 R-CAR V3U 一样,英伟达 Orin 也是一个系列产品。
后者的低端产品可能只有 2 到 4 个 A78 内核,20 到 40 TOPS 的 AI 算力,可能没有 Ampere GPU 或少数核心。
4、高通 Snapdragon Ride,进击的移动芯片霸主
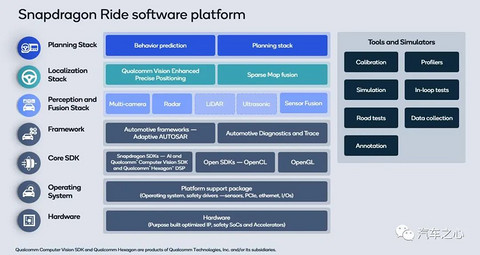
关于高通 Snapdragon Ride的公开信息很少。
高通的核心业务还是在移动端,因此高通的策略是最大程度地利用手机领域的研发成果。

按照这个策略,高通最新的Snapdragon 888(即 SM 8350)芯片会最接近 Snapdragon Ride SoC。
高通的 Ride 平台和英伟达类似,也是基于 SoC+AI 加速器的分离方式。
高通声称 888 芯片会采用三星 5 纳米 5LPE 工艺制造,并且是两年半前就决定的。
但目前三星的 5 纳米还没有一个厂家使用,而台积电的 5 纳米已经经过苹果 A14 验证过。
论关键指标晶体管密度,三星的 8 纳米与台积电的 12 纳米差不多。
三星的 5 纳米跟台积电的 10 纳米差不多,明显低于台积电的加强版 7 纳米。
但台积电 5 纳米产能被苹果包了,高通只能找三星。
在 888 芯片上:
Arm 的 Cortex-A78 和 Cortex-X1 都是基于上一代 Cortex-A77。
但这两款 Arm 处理器的设计目标不同:
Cortex-A78 侧重于提供更高的每瓦性能,同时体积更小,而 Cortex-X1 则是追求最大性能。
Cortex-X1 是 Arm「CXC 项目」的第一款商用产品。
性能方面,Cortex-X1 将比 Cortex-A77 提高 30%。
与 Cortex-A78 相比,Cortex-X1 的整数运算性能提升了 23%。
Cortex-X1 还拥有两倍于 Cortex-A78 的机器学习能力。
Cortex-X1 就相当于「超大核」,它在架构设计上与 Cortex-A78 如出一辙,但几乎在每个地方都进行了扩展。
ARM 对 Cortex-X1 的定义是「可定制」移动平台,芯片商可以根据预算和需求向 ARM 提出要。
然后 ARM 再根据不同的应用场景,调整 Cortex-X1 各个模块的规格设计。
即便 S888 非常强大,但因为三星的 5 纳米工艺,晶体管密度远不如台积电 5 纳米,也不如台积电 7 纳米。
因此,S888 的单核性能仍然落后苹果上一代的 A13,跟台积电 5 纳米的 A14 比差距更是非常明显,A14 比 S888 单核跑分高 41%。
GPU 方面更能凸显三星工艺的落后。
根据 GFXBench Aztec 测试:
A14 峰值达到每秒 102.24 帧
A13 达到 91.62 帧
S888 只有 86.00 帧
华为的麒麟 9000 是 82.74 帧。
AI 性能方面,S888 得分很高,用 UL Procyon 测试 AI 推理为 32228。
华为的麒麟 9000 是 12596,S888 几乎是麒麟的三倍。
S888 理论值 26 TOPS,也比苹果 A14 的 21 TOPS 高。
Ride 平台应用于自动驾驶领域,因此高通可以砍掉 S888 上的 X60 5G Modem,留出更多地方放 NPU,AI 算力估计可以达到 30-40 TOPS。
考虑到成本和车规,高通不会增加太多 AI 算力,因为高通还留了加速器,也就是类似英伟达 A100。
5、华为 MDC,国货之光,封锁之下何去何从
华为的自动驾驶计算平台由车 BU 下的 MDC 产品部负责。
MDC 上采用的 AI 协处理器是昇腾系列芯片,而 CPU 来自华为的泰山服务器事业部,即鲲鹏系列芯片。
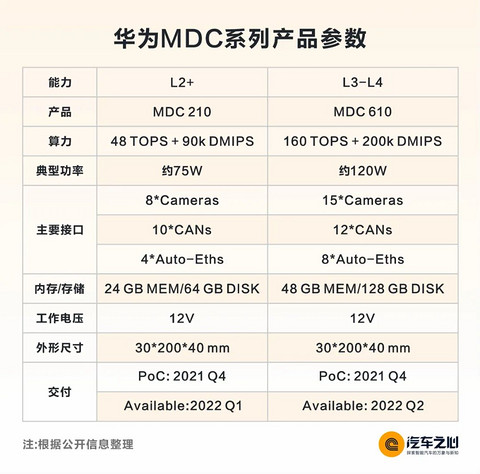
MDC 全称是Mobile Data Center,移动数据中心。
MDC 的成员部分来自华为的中央硬件部,后者以开发 ARM 服务器为主要业务,之后转到自动驾驶领域。
MDC 的芯片部分仍由海思提供。
MDC 目前主打两款产品:
一款是用在 L2+ 上的 MDC 210
另一款 MDC 610,主要用在 L4 上
MDC 210 的 CPU 部分未知,AI 处理器是昇腾 310。
MDC 610 的 CPU 很可能是鲲鹏 916,AI 处理器是昇腾 610。
鲲鹏 916,在海思内部代号是 Hi1616,是 2017 年的产品。
其采用 32 核 ARM A72 并联设计,最低功耗 75 瓦,标准 TDP 功耗 85 瓦,对标英特尔至强系列服务器 CPU。
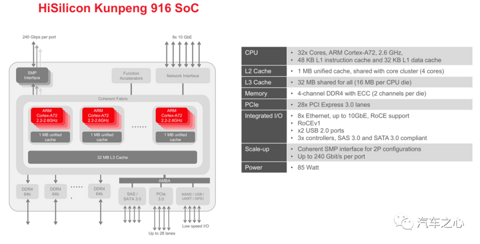
华为鲲鹏 916 参数与内部框架图如上:
采用了16 纳米工艺,也就是说中芯国际能够代工。
鲲鹏系列更高级的产品是 920,海思内部代号 Hi1620,采用了 16 - 96 核设计,华为自研的架构,ARM v8.2 指令集,7 纳米工艺。
鲲鹏 930 计划采用 5 纳米工艺。
上面说到,华为 MDC 的 AI 处理器主要是昇腾 310 和 610。
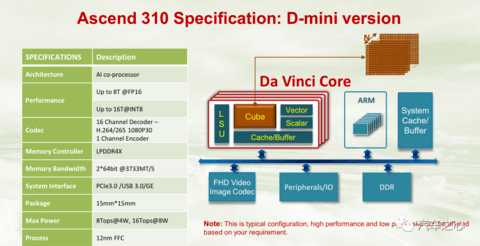
按照华为的路线图,官方原计划在 2020 年推出昇腾 320、610 和 920,但一直到目前都没有消息。
昇腾 310 是采用台积电 12 纳米 FFC 工艺制造,于 2018 年推出,因此性能一般,只有 16TOPS 算力。
从华为的官方介绍看,昇腾 920 和 610 都是定位于服务器深度学习训练用的,不是用于车载应用。
这两款处理器有明显的 Cowos 多存储芯片封装设计,这种封装成本也很高,不适用于成本敏感的领域。
6、谁是最强芯片?
整体回顾:五大厂商中,瑞萨主打超高性价比,并且设计之初就有整车厂支持。
在日系车企中,除了国际化程度比较高的日产,其他厂商毫无疑问都会倾向于瑞萨的 V3U。
瑞萨在车规安全方面积累较多,这也是德系厂商非常关心的。
因此出身车载半导体领域的瑞萨比较受日系和德系厂商青睐。
Mobileye有超过 6000 万片出货,有庞大用户基础,美系、韩系还有国内自主品牌都倾向于 Mobileye,但目前 EyeQ 系列产品推出速度太慢。
这也是理想、蔚来等多家新晋厂商放弃 EyeQ 平台的原因。
英伟达性能一流,至于价格,用黄教主的话说,「买得越多,省得越多」。
新兴造车企业追求高性能,蔚来、理想、小鹏几家手上也有几百亿元的现金储备,英伟达在其中颇受青睐。
高通Snapdragon Ride 平台与瑞萨类似,主打性价比,并且高通的原厂支持力度比较大。
目前,长城以及一家众所周知的造车新势力头部公司已经选择了 Ride 平台。
华为最大的掣肘因素在于芯片的产能。
目前中芯国际的 14 纳米工艺不算成熟,从财务数据看,中芯 14 纳米业务仅占其收入的 1%。
眼下中芯国际也被美国制裁,工艺和产能提升都十分困难。
即便解除封锁,华为也不会对外单独销售芯片。
无论车企选择使用哪个平台,都需要芯片原厂提供充足的支持。
在这方面,瑞萨高阶的原厂工程师都在日本,支持力度较差。
英伟达人力资源有限,据说其支持力度也不太友好。
高通在经历移动端的多年磨砺,非常适应于为几十个厂家做支持。
结合 Mobileye 的推新节奏,我认为,最终高通和瑞萨有希望胜出。
参考信息:
[1]https://www.eenewsautomotive.com/news/we-need-standardized-criteria-autonomous-driving/page/0/4。
[2]https://eetimes.jp/ee/articles/2012/21/news067.html,CNN-IPも自社で開発したものだ。理論上の最高性能は60TOPSで、1W当たりの性能は最高で13.8TOPS。




















