
智驾VLA 阵营,理想、元戎双强卡位



上半年智驾界的动作,无非两类。
一路玩家向上进击 L3,尊界 S800 会搭载 ADS4 版本实现 L3,小鹏也将发布的 G7 称为「首个 L3 级 AI 汽车。」
另一路玩家则向外拓展智驾边界,元戎和理想陆续发布了语音控制智驾、理解路牌等需要系统具备长推理思维链的新功能。
水面之下其实是一场关于技术路线的分歧。
前一派认为未来通往完全自动驾驶的技术不是 VLA,而是世界模型。理由包括:泛仿真会代替 VLA 登上 C 位,而自然语言的解释能力并非智驾的核心技术等等。
另一派则坚定认为下一代智驾还是 VLA。
元戎启行 CEO 周光最近在火山引擎 Force 大会上直言「VLA 是实现完全自动驾驶的必经之路。」类似地,李想也坚定认为「必须使用 VLA 才能实现 L4 自动驾驶。」
VLA 路线被重新推至风口,但这一次 VLA 需要解决一些更难的问题。
01、剩下的问题,都是最难的
目前主流车企、智驾玩家都进入到了全国都能开,高速、城区都达到了可用的状态。
但从可用再到爱用、好用,差距很大。
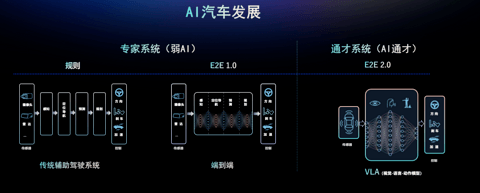
本质上是因为很多玩家还处于两段式端到端系统中,周光把这称为端到端 1.0 版本,而 VLA 则是端到端 2.0 版本,核心是要打造防御型驾驶能力。
在这个成熟度比较高的智驾市场中,剩下往往是最难解决的问题。
第一类问题就是黑盒问题。
在端到端的「黑盒子」模式中,模型行为缺乏可解释性。
这种不可解释性会导致两个问题,一方面辅助驾驶系统可能会突然不知缘由「抽风」,做一些违背正常司机驾驶的决策,比如突然加速等,这种反常识决策会让用户产生不信任感。
另一个层面就更危险了,系统遇到不能处理的场景紧急退出,此时如果接管不及时,就会导致事故发生。
第二类问题是防御型驾驶不够。
防御型驾驶在于能不能预判路况,这也是新手司机跟老司机的区别。
最典型的就是高架桥的桥墩盲区。匝道汇入主路时,一侧的桥墩会遮住司机大半个视野,新手司机可能察觉不到,但老司机会提前减速观察,避免突然出现车辆。

交管部门数据显示,在众多交通伤亡事故中,因内轮差和盲区引发的事故占比达到 70% 以上。
现在多数智驾遇到鬼探头只能做到急刹避让,但防御型驾驶是要能提前结合场景,预知鬼探头风险提前减速。
第三类问题是人机交互太过于机械化。
大多数车辆进入辅助驾驶状态后,用户决策仅限于「不接管」和「接管」,没有专属用户驾驶风格的定制化调节,这也是系统更容易决策偏离用户预期的原因之一。
归根结底,整个行业还没有彻底解决用户安心感的问题。
现在业内针对提升智驾性能有两个方向:一种是视觉-语言-动作模型 VLA 路线,它在感知与动作输出之间引入了语言作为中介,通过三者融合来解决端到端泛化和可解释性的问题,进而提升系统安全感。
因此,以理想、元戎为代表的 VLA 路线,是端到端 2.0 版本,侧重车端,需要运用语言模型的能力。

第一步:在 input 输入层输入视觉(BEV 图像+点云)和文本输入(语言转文本的指令);
第二步:由编码器把文本和图像、点云转换为特征向量和语义向量;
第三步:将视觉和文本两种模态信息融合成统一的表征,VLA 就能同时理解图像和文本指令;
第四步:在 output 输出层,解码后系统输出控车轨迹和人类可读、可理解的思考过程。
另一种是世界模型路线。
本质是在云端建造一座工厂,通过引入真实数据做场景泛化,形成生成大量虚拟驾驶场景来训练、评价系统,进而提升系统能力。以小鹏、华为、蔚来代表的世界模型路线,更侧重云端,会消耗更多储存和算力。
这两种路线并不矛盾。
VLA 路线也结合了部分与驾驶数据相关的世界模型。
比如,李想提出 VLA 可以拆解为预训练、后训练和强化学习三个层面。强化学习中最重要的一步就是在世界模型里闭环学习,引入舒适度、碰撞、交通规则等规则来打磨、反馈,让 VLA 比人类开的更好。
因此两种路线只是侧重点的不同。
周光向汽车之心透露他们押注 VLA 的原因之一:元戎要运用语言模型,并不只停留在表面的语音功能,而是更看中以语言为媒介的推理能力,对世界常识有更全面的认知。
02、VLA 第一阵营:理想和元戎
VLA 动静最大的有两家,一家理想,一家元戎。
两个玩家的共性就是坚定押注 VLA。
早在今年 1 月,元戎启行就对外剧透了 VLA 模型,周光认为自动驾驶会跟着语言模型的水平走,而大语言模型发展会经历小学生—大学生—垂类专家三个阶段。
对应的传统规则模型就像是弱专家系统,但当智驾玩家都开始利用端到端解决问题,就进入了 AI 的「通才系统」。
类似的,今年 5 月份李想也讲 AI 汽车发展,类似比为昆虫、哺乳动物和人类三阶段,分别对应规则算法、端到端+VLM、VLA 司机大模型。

VLA 技术路线下开发出的功能也十分相似。
两个玩家都重新定义了「语音控车」。
此前,语音控车指通过语音唤醒车机、控制座舱。现在元戎和理想将语音控车升级——用户能在车辆在辅助驾驶中,语音控制车辆的动作、车速、车道选择等,甚至还释放了会豪车识别功能。
如果前车属于豪车,智驾系统就会更加谨慎。语音控车的背后就是 VLA 系统对场景深刻精准的理解能力。
元戎和理想最大的区别,在于重心不同。
理想作为车企更注重智驾和智舱的平衡,而元戎作为智驾供应商,主要侧重在智驾上。
除了语音控车之外,元戎启行还释放了空间语义、异形障碍物识别、文字类引导牌理解三大功能。
空间语义功能,即 VLA 可以解决盲区场景设计的问题。
这就相当于为系统装上透视眼,预判现实世界的交通盲区。
周光展示了一张动图,车辆在右侧行驶,右侧有公交车,为了通行效率变道至左侧,标志牌上提示「注意横穿,减速慢行」,车辆在看到公交车微微刹车后,也跟着减速慢行。

这背后的逻辑是车辆理解了指示牌上文字信息——看到公交车在人行道前突然减速——系统推理盲区有行人横穿——最终提前减速、谨慎通行。
之所以能提前预判行人穿行,就取决于 VLA 的长思维链。此前端到端 1.0 版本只能推测几秒之内的路况,VLA 思维链更长,推理能力更长更远。
在异形障碍物识别上,元戎 VLA 模型的能力更强。
上一代端到端的识别异形障碍物属于智驾的算法长尾问题,过去经常被归类为 1% 的极端路况。
但是依靠 VLA 模型,即便碰上三轮上堆满形状、材质各异的货物,仍然能识别出它的本体是一辆三轮车。

最后,VLA 也可以加强系统对文字类引导牌的理解能力。
一个文盲想要开好车很难,元戎启行的 VLA 模型能够识别理解各种图形、文字类路牌信息,按照路牌引导内容行驶。
从元戎释放的测试动图来看,即便在是复杂的八车道路口,系统仍然能理解路牌信息,选择正确道路行驶。

以上这四类功能都隐约透露出元戎的野心——用 VLA 打造出能防御型驾驶的 AI 司机。
据悉,元戎的 VLA 模型将会在第三季度量产上车 5 款车型,接下来智驾是否具备更长远的思维、推测能力,VLA 能否大规模量产上车,也是下半年智驾玩家们能否进入 VLA 第一梯队的关键。
03、极致的 VLA,通用人工智能的「神之一手」
VLA 不仅可以通向极致的智驾,同时极致的 VLA,也能造出物理世界的通用人工智能。
9 年前 AlphaGo 和李世石决战的第二局中,将第 37 手落在了棋盘第五线,起初大多数专家认为 AlphaGo 失误了。

因为很少有高段位选手会开局就如此激进,但正是看似充满不确定性的 37 手棋,脱离了人类围棋选手的传统思维模式,走出了 AI 最独特的一步。
本质上就是因为 AlphaGo 每一步都能推演得到 150 手以后的格局。类似地,拥有长思维链能力的 VLA,很可能是通用人工智能的「神之一手」。
但要想用 VLA 打造物理世界的通用人工智能,必须完走三个技术阶梯。
第一层楼梯是基本功,要完整的积累智驾数据,开启量产交付。
2024 年是元戎的量产元年,元戎除最核心的落地项目蓝山全新智驾版,还开启了长城高山、smart 精灵 5 以及海外车型的量产项目,其中,蓝山全新智驾版上市 2 个月城区智驾激活量就超过了 1.3 万辆,打造出小爆款。
第二层楼梯,是用 VLA 技术占领时间和量产高地。
从时间线来看,元戎是业内最早将 VLA 概念引入智驾领域的玩家。在量产上,元戎正在与浙江某头部车企洽谈项目,预计今年元戎启行累计出货量将会达到 20 万辆。
第三层楼梯,就是利用 VLA 模型复制到所有可移动的物体上,打造物理世界人工智能 RoadAGI。
通向 RoadAGI 的技术,依旧是 VLA。
首先,VLA 的技术概念本身就源自于机器人界。2023 年谷歌在其发布的 RT2 中提出 VLA 模型,这也是全球第一个控制机器人的 VLA 模型,不仅能让机器人解读人类的复杂指令,还能看懂眼前的物体,并按照指令采取动作。
VLA 被公认为是机器人编程的重大飞跃,一年后周光就将 VLA 迁移到智能驾驶,现在元戎利用 VLA 模型开发的四大功能,也在间接证明智驾和机器人的底层技术可以共享。
其次,VLA 具备四个核心特性在更大范围的物理世界同样适用。
架构继承:让 VLA 可以直接复用成熟的基座模型架构,不用重新造轮子;
动作 Token 化:可以把物理世界的一系列行为表述为语言进行推理;
端到端学习:感知、推理、控制一体化,减少了信息传递损失;
可泛化性:能让系统具备举一反三的能力;
今年年初,元戎启行就曾在英伟达 GTC 大会上小试牛刀,公布过 RoadAGI 最新进展。

目前,通过 Spark 1.0 元戎已经可以实现配送的闭环:一台移动机器人可以自动识别店铺、红绿灯、过闸机、摁电梯,最终把货物从店铺送到办公室。
跟传统无人车的区别是,这台移动机器人行走不依赖高精地图,且拥有对周边环境的理解能力。相比之下,目前大多数机器人都是基于规则做遥操控制,而元戎的思路是做机器人的规划和大脑,用技术解决智能体的移动问题。
接下来,元戎启行将和火山引擎,基于豆包大模型,共同研发 VLA 等前瞻技术,打造物理世界的 Agent。
就像周光所言,智能汽车是人类首个达到千万级数据体量的机器人。通向 RoadAGI 不止需要极致的 VLA,还取决于前期的数据、工程经验积累。
只有在第一、第二层阶梯积累了足够多的量产数据闭环与端到端能力,才能迈上第三层楼梯。
元戎转向 RoadAGI 更像是自我能力的延伸,就像元戎的技术演变一样,从提出前融合再到端到端,再将 VLA 引入智驾,这些都是技术自然发展的过程。
智驾可能是一场有限游戏,但接下来元戎投身的物理 AI,更像是一种能持续获得成长的无限游戏。




















