
智协慧同:车云数据底座打造智能汽车的先进生产力
基于车载数据库打造智能汽车的数据底座。智协慧同在2021年完成国内首个车云计算架构的量产落地交付,围绕车云计算在数据方面进行了诸多探索。
智协慧同合伙人兼战略总监胡勇表示:“汽车时代正迎来范式升级,数据驱动成为车企的核心竞争力。针对数字化转型,最重要的是以用户为中心,构建起产品全生命周期的数据驱动能力。”

胡勇 | 智协慧同合伙人兼战略总监
以下为演讲内容整理:
数字化转型的关键在于怎样将底层车辆的数据,用户的数据更好的采集起来,更高效的利用起来。智协慧同从基础软件的角度,从计算架构解决汽车数据问题。作为创业型公司,我们在2021年实现了行业首个车云计算方案的量产交付。目前合作客户已超过10家车企,我们致力于通过数据更好地连接产业链条。
汽车迎来范式升级,数据驱动成为车企核心竞争力
目前汽车的-进化范式发生很大的变化。以前我们通过经验,通过写代码把策略固定在控制器上,全生命周期中车辆都不再迭代。现在,智能汽车依靠各种模型,各种策略来让车辆更智能,模型的背后是大量数据的驱动。如今汽车数据的增幅飞快,高级自动驾驶的汽车每天产生的数据量超过20TB,这种速度还将持续。未来,车企如何构建数据驱动的能力是竞争的核心所在。
数字化转型需以用户为中心,构建产品全生命周期的数据驱动能力。我以前在车企做过产品规划、做过智能网联,现在在软件公司做基础设施。在做很多事情时,我会充分考虑之前做产品规划遇到的问题。比如在产品规划阶段,定义产品时怎么定义功能和性能?以前,好多时候都是拍脑袋,或者买数据、找对标,但都是靠不太可信的数据做的决策。现在,从产品规划到开发、售后,到用户运营以及持续的升级,我们要把车辆产生的数据贯穿起来。只要将这个环节做好,数字化转型才能有所支撑,我们的决策也将是依靠科学的数据。
车上的数据非常复杂,车辆数据、位置数据、应用数据、驾驶行为特征数据,道路和环境特征等数据维度日益增多,高达20000+;这些信号又是毫秒级的高频信号,数据种类繁杂,而且这些数据的特点是价值稀疏,有价值的数据不到10%。这些数据如何采集?过去10年车联网都在这被卡住了,很多有价值的数据上不了云,无法驱动价值。
比较有成功的数字化实践案例是特斯拉。特斯拉基于车云计算构建数据闭环,从车端进行数据采集、存储,在云上进行数据归集汇总,进行数据开发。并基于这套架构打造出来了高价值的应用生态,包括FSD的快速迭代、优化;其成本和质量控制也都是靠数据决策。
从特斯拉的方案可以看出,数据驱动被划分为四个层级:L1是灵活的高精数据获取能力。但就这一层,90%的车企也做不到;L2是敏捷的数据开发能力。传统方式会把很多业务人员需求给到IT,IT写代码,在云端做大数据分析,从业务人员到IT人员沟通效率极低。最后把云上写好的模型跨车云进行部署,又造成了时间和效率的浪费,这是L3级的数据闭环能力。再往上是L4开放的数据生态能力。
从L1-L4的数据驱动能力,我们进行了数字化的定义。现在,特斯拉把整套链路跑通了。我们也提出了类似的一套计算架构,这是我们基本的产品组成,也是车云计算的框架。
EXCEEDDATA——全面赋能数据驱动
首先在车端,我们用了边缘计算的中间件软件和持续的数据库。通过车端的存储和计算,我们能帮助业务人员采集其需要的、有价值的数据。边缘计算将业务人员的需求直接建模、下发,还能够采集各种特殊场景,或者各种事件数据。
同时,车端的数据库可以对毫秒级的信号进行高效采集,对结构化数据进行上百倍的无损压缩,并支持数据的周期性存储。针对车企比较关注的数据,可以进行周期性的常规采集,把数据采集进行分类。
今年,我们又推出了“灵活数仓”的概念,帮助业务部门更好地基于基层产品,搭建数据应用,进一步封装产品。
在前端给到业务人员低代码的建模工具,可以让不会写代码的工程师通过拖拉拽快速建模,建好的模型可以在云上跑和车上跑,省去了模型迭代的过程,实现了数据从高效采集、灵活采集到模型迭代,再到模型下发,整个数据闭环非常高效,效率提升几十倍以上。
基于车端数据底座,我们深耕三大核心应用场景,赋能整车数智化。一是整车数据智能。包括底盘、座舱、车身、动力等,我们都需要在上面通过边缘计算和各种业务模型提取有效特征,并将有效的特征数据反哺给策略和模型,让它能够持续迭代,解决各种问题。
二是智能诊断。汽车的智能化带来了产品的复杂度提升,但开发周期在不断缩短,很多问题在开发中不能识别,不能定义,这需要一套在线智能诊断系统。在产品交给用户后还可以快速发现异常,快速解决问题。
三是自动驾驶。我们的架构可以帮车企进行快速的Corner Case数据采集迭代,从Corner Case的建模,到下发,再到数据回传,基本上是进行分钟级的迭代。
基于上述数据底座,可以实现的数据场景比较多,我们的产品部署也很灵活。现在,我们已经与很多车企展开了合作。
图形化、可调整、敏捷支持业务部门的灵活数仓
关于“灵活数仓”,它区别于传统数仓,使很多业务提数据需求时,可以通过工具链进行拖拉拽,就可以把灵活数仓的各个层级进行灵活搭建。如果业务需求发生变更,还可以自己快速调整。传统数仓的数据需求汇集非常多,每次调整都要通过写代码,非常麻烦。我们直接拖动模块,按照需求去拖即可,效率得到了大幅提升。
首先当大业务模块变成小的灵活模块时,企业对计算资源的使用也会更高效。可以使很多数据更高效地实现业务价值。对比来看,传统数仓规模大而全,但颗粒度非常大,不能满足各个业务部门的需求,很多车企建了数仓但业务部门不用,因为解决不了问题,很多需求在不断变化。尤其是在智能汽车初级阶段,家对数据的认知、使用都还处于初期,不可能清晰地定义数据需求,而灵活数仓可以支持实时的迭代更改,能够更快地满足业务数据需求。
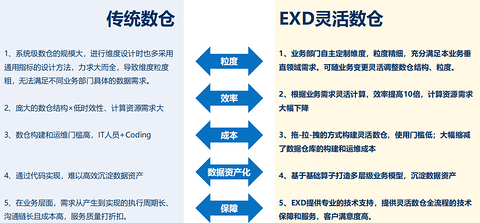
图源:智协慧同
第二传统数仓结构庞大,每次改动效率都较低,都会把大批量数据进行无效计算;在灵活数仓上,针对具体模块来调用相关资源来进行计算即可,效率提升了十倍。
第三传统数仓从构建到运维门槛很高,需要IT人员写代码更改。灵活数仓通过拖拉拽就可以快速迭代,由业务人员迭代数仓的设计。
第四帮助车企沉淀更多的数据资产。通过底层算子可以打造多层业务模型,这些模型只要通过内部验证就可以作为标准,在车企和云端存储,相关业务需要时直接调用即可以,车企内部不用再重复造轮子。
第五灵活数仓有专门的人服务车企,从而更好实现整套数据的自动化生产线的搭建。
打通数据全链路,助力产业数字化转型
我们的产品从车端基础软件到云端工具,从数据采集,到存、算、用和开放给生态,全链条进行打通,打通后在数字化转型时,能很好地利用最重要的数据信号,对产品进行升级,对功能性能进行迭代。同时还可以实现降本提质。
举个例子,在车端搞边缘计算引擎和数据库,车企最关心的是CPU上到底占多少资源,以及运行这些资源时稳定性如何。为了上量产车型,我们已经把性能提升了一倍。现在,在客户的单核A55上,大概会占7%-8%的CPU算力,而且CPU占用是非常平滑的直线,不会上下浮动特别大,不会影响整车的其他功能。
通过量产实践,我们真正打通了从底层基础设施到上层数据应用的数据链条,从数据到价值进行流转,未来,还可以帮助车企创造新的商业模式。这是基于技术产品打造的全生命周期的数据驱动能力。
(以上内容来自智协慧同合伙人兼战略总监胡勇于2023年9月18日在2023第二届汽车数字化转型大会发表的《车云数据底座打造智能汽车的先进生产力》主题演讲。)
来源:盖世汽车
作者:叶壹贰
本文地址:
以上内容转载自盖世汽车,目的在于传播更多信息,转载内容并不代表第一电动网(www.d1ev.com)立场。
文中图片源自互联网,如有侵权请联系admin@d1ev.com删除。














