
HiEV洞察 | AI芯片禁令下,本土智驾承压能力全解析


作者 | Alex博士
编辑 | 德新
一、禁令加码给智能汽车业的冲击
6月末大洋彼岸的一则新闻再次触动了中国AI产业界的神经。
据《华尔街日报》援引消息人士透露,美国正在酝酿新一轮的AI芯片禁令,在去年禁令的基础上,进一步 扩大限制范围。
新禁令最快可能7月落地,届时中国公司极有可能连A800等性能阉割版AI芯片都无法获得,目的就是为了进一步减缓国内通用AI算力的发展速度,在AI赛道持续打压国内科技产业。
上一轮禁令出台于去年9月。当时美国商务部发布了对华半导体出口限制新规,以英伟达A100为基线,要求限制超过基线性能的AI芯片对华出口,英伟达A100/H100和AMD公司的MI100/MI200等大算力GPU芯片均在限制范围内,这些芯片均是云端数据中心的主流加速卡(GPGPU)。
为了减少业务冲击,英伟达迅速调整产品策略,相继推出了 A800和H800两款中国特供版芯片,以满足合规要求。虽然两款芯片的纸面算力与A100/H100无异,但互联带宽只有后者的一半,意味着集群后的算力规模会受制于卡间互联的带宽。

英伟达A100芯片 来源:官网
自去年底以来,以 ChatGPT为代表的AIGC大模型赛道突然崛起,导致高性能GPU芯片需求暴涨。
产业界普遍认为,大模型是继智能驾驶之后又一个具有广阔市场前景的科技主赛道,中美两国都在积极布局抢占先机。在此背景下,美国可能意识到此前的芯片禁令力度不够,需要追加新禁令,核心是帮助美国公司在核心AI赛道对中国公司保持绝对领先地位。
AI芯片不仅是大模型的基石,也是推动智能驾驶落地和进化的核心“生产力工具”,潜在新禁令将对智能驾驶产业产生哪些影响,是智驾从业者需要认真评估的课题。
更令人担心的是,如果禁令继续加码,AI芯片限制范围不断扩大,将对智能驾驶行业产生哪些新的冲击。在回答这两个问题之前,需要对AI芯片类别及其智驾应用场景做一些基础梳理。
二、AI芯片分类:云端与边缘、训练与推理
AI芯片也被称为AI加速器或计算卡,即专门用于处理人工智能应用中的大量计算任务的模块(其他非计算任务通常由CPU负责)。
AI芯片产品种类繁多,通常有三大分类维度: 应用场景、部署位置以及芯片架构。
应用场景:分为训练(Training)和推理(Inference)。
训练芯片是用于构建AI神经网络模型的高性能算力芯片,主打高并行数据吞吐率和低功耗;
而推理芯片,则是利用已训练完成的AI模型进行推理预测,基于输入数据输出推测结果,侧重低延迟和低功耗,对算力要求偏低。
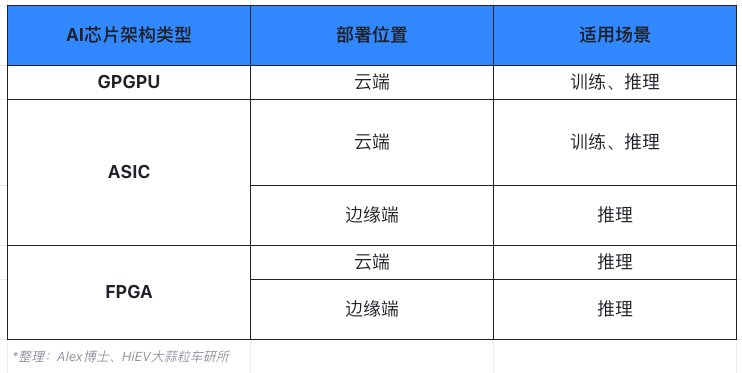
部署位置:分为云端(数据中心)和边缘端。
云端数据中心具有强大的计算能力和海量的数据,承担模型训练以及推理任务(例如目前爆火的AIGC大模型),对AI芯片要求是高性能和高吞吐量,数据中心是目前高性能计算AI芯片核心应用场景;
边缘端则使用训练好的模型进行直接推理,更加注重实时性和低功耗,主要应用场景包括机器人、智能驾驶、手机、物联网设备等。
芯片架构:分为GPU(一般特指GPGPU)、ASIC和FPGA。
GPU 作为最早从事并行加速计算的处理器,具有高并行结构,在处理图形数据和复杂算法方面拥有比 CPU 更高的效率。
ASIC是一种面向特定应用场景的专有AI芯片,通过算法固化实现极致的性能和能效,平均性能强、功耗低和性价比高,但前期投入大、研发时间较长。
FPGA是一种半定制化芯片,在制造完成后仍然可以对芯片进行灵活软件功能配置,以满足用户独特需求,具有可编程性、高并行性、低延迟和低功耗等特点,在云端和边缘端的推理领域具有很高的应用潜力。
三、AI芯片在智能驾驶中的应用
GPU作为通用大算力芯片一般应用于 智驾数据中心,赋能智能驾驶神经网络训练,包括数据自动标注、环境感知、多模态融合以及规划控制等各个环节。
随着智驾渗透率的提升,车端采集并上传到云端的各类信息数据量快速上升,亟需具有大规模AI处理能力的数据中心支撑。
去年10月的Tesla AI Day曾透露其超算中心拥有14000个GPU, 共30PB的数据缓存,每天有500000个新的视频流入。
比亚迪也特别注重云端海量数据采集,目前已经积累了150PB以上的数据,并且每天新增1PB数据,这些数据被用于下游的训练任务,而且预计今年还会累计有6亿公里的数据,并在未来几年通过研采车辆以及量产车队实现指数级的数据储备,以解决智驾的长尾问题。
目前 国内多家OEM和Tier 1均在积极建设智驾数据中心。
蔚来2022年就曾宣布与英伟达合作,基于A100打造自己的数据中心;
小鹏汽车与阿里云合作在乌兰察布建设了智算中心“扶摇”,宣称云端算力可达600 PFLOPS;
毫末智行发布了和火山引擎合作的“雪湖·绿洲”智算中心,称其算力规模为670 PFLOPS;
理想汽车同样宣布了与火山引擎合作在山西打造智算中心,采购的公有云服务算力达750P FLOPS;
吉利汽车则和阿里云在湖州成立了星睿智算中心,拥有810 PFLOPS(F的算力。
上述智驾数据中心的核心AI芯片基本都是基于 GPGPU(以英伟达A100/A800为主)。
行业标杆Tesla的规划则有所不同,Tesla正在基于其自研的ASIC训练芯片D1来打造专属的Dojo超级计算机,每个训练模块将由25个D1芯片组成,计算能力将达到每秒9千万亿次(9PFLOPS),数据带宽可达36TB/s,基本上实现了算力密度和数据吞吐能力的最大化。

Dojo超级计算机
ASIC作为专用大算力AI芯片,虽然被Tesla选择用于构建数据中心,但其核心场景仍是车载边缘推理端—域控制器。目前域控制器中大量使用ASIC AI芯片,提供大算力高能效比的推理能力。
车端智能驾驶的实现需要依靠激光雷达、毫米波、摄像头等多种传感器对道路信息进行感知,将感知数据上传到域控制器进行综合处理,以识别各类动静态道路参与者、道路结构化信息和可行驶区域,控制车辆以规划好的路径进行自主行驶。
整个过程对数据处理的要求非常高,不仅需要应对海量的环境实时信息,还要在极低时延和较低功耗下进行,时延事关行车安全,功耗则会影响续航,同时域控平台的成本需匹配车辆售价,芯片成本约束较大。这些因素导致GPGPU无法部署在车端,只能使用专有ASIC AI芯片。
面向域控制器的ASIC AI芯片中属英伟达布局最早,生态打造也最为全面和成熟。目前其车载端量产芯片包括Xavier、Orin X。
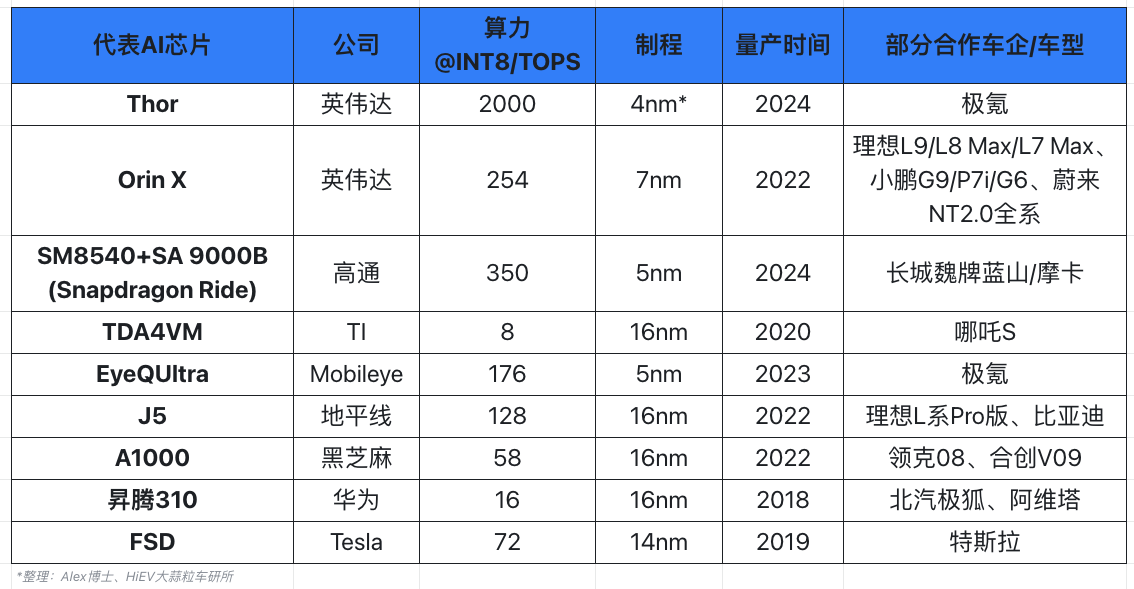
其中 Orin X是目前最具代表性的域控主流芯片,于2022年量产,OrinX SoC包含170亿晶体管,提供254TOPS(INT8)性能,基于7nm的制程工艺,功耗仅为50W,凭借英伟达CUDA出色的生态支持,Orin X在过去一段时间成为众多国内车企的首选。
英伟达已经官宣了下一代车载自动驾驶芯片平台Thor,算力达到恐怖的 2000TOPS(INT8),预计2024年量产。
另外国外如高通、Mobileye也提供大算力车载AI芯片,但量产时间偏晚。

英伟达Orin X芯片

地平线J5芯片
国产域控制器AI芯片这几年发展也非常迅速,成果喜人,代表公司有 地平线、黑芝麻智能等。
其中地平线产品商业化进展颇为迅速,其明星产品J5采用台积电16nm工艺,单芯片算力128TOPS(INT8)、35W功耗、支持16+路摄像头,是目前量产产品中性能仅次于英伟达的智能驾驶域控芯片平台。
黑芝麻智能则主打华山系列AI芯片家族,包括A1000、A1000L和A1000 Pro,提供不同的算力等级匹配各类用户需求,针对L3及以上,正在开发目标算力为250+TOPS的A2000,黑芝麻智能近期已经向港股提交了上市申请。
FPGA在智驾领域有两重应用身份。
第一重应用是作为AI芯片起加速硬件的作用,面向推理阶段,FPGA相比GPU具有低延迟、高并发的优势,但是智驾云端的实时性要求并不高,更多是离线处理,所以FPGA的独特价值并不明显,这和IT公司的实时推理系统并不一样。
而在车载域控制器(边缘推理)领域,FPGA高性能推理加速优势较为明显,针对不同的量产车型项目配置灵活。
以宏景智驾为例,基于赛灵思的车规级XA Zynq UltraScale+MPSoC平台,推出了具备 多核异构架构的高级自动驾驶域控制器—Gemini ADCU,主打高性能边缘计算。但受制于成本和综合指标,FPGA域控平台目前并不是主流选择。
第二重应用是作为智驾传感器SoC对原始传感信号进行高速实时处理,发挥其实时性好、配置灵活、开发友好度高等优势,目前主流双目感知系统、激光雷达以及4D Radar等ADAS硬件系统均有FPGA嵌入式应用的案例,Xilinx和Altera占据车载FPGA绝对主导地位。
以激光雷达为例,FPGA用来对光电信号进行实时运算处理,基于ToF原理计算出每秒上百万个点云,整个过程要在极短的时延下达成。目前禾赛、速腾、图达通皆选用 Xilinx的ZynQ系列车规芯片。
实际上,作为车载传感器SoC处理器的FPGA,其车规等级、功能安全等级及开发生态相比于计算指标反而更加重要。
四、AI芯片禁令对智能驾驶的影响
先说说FPGA,基于客观审慎分析,新禁令对车载FPGA的影响并不大。
虽然目前车规级FPGA基本来自于美国的Xilinx和Altera,但车载FPGA算力较低,属于大消费电子领域范畴,且种类型号繁多,战略性不像其他大算力AI芯片那么突出,所以美国尚不会有特别的针对性禁令。
而且国产FPGA替代已经开始了,虽有些差距,并不是0和1的代际差别,关键时候是可以顶上去的。
但是禁令下的 GPU和ASIC芯片的处境就没那么乐观了。
随着美国新禁令可能到来,智驾数据中心能力的建设将受到负面影响,很多高性能的GPGPU芯片无法正常采购。
虽然国产GPGPU公司从之前禁令中受益,并在“国产替代”概念下得到了格外关注,如天数智芯、寒武纪、黑芝麻智能、墨芯人工智能、燧原科技、壁仞科技、沐曦集成电路等,不管是迎合客户市场还是配合产业政策,聚光灯下的产品策略显得较为激进,而整体芯片设计能力、生态体系以及系统可靠性距英伟达还有较大差距(英伟达的核心算力壁垒是由GPU+ CUDA所组成的,近17年积累,软硬件生态共生发展),迎头赶上并非一朝一夕的事情,远水解不了近渴,智驾数据中心的算力升级必然会被迟滞。
不幸的是,行业内卷加剧了智驾数据中心目前的算力瓶颈,尤其是随着BEV-Transformer架构的引入以及大模型与智驾领域相结合,进一步推升了智驾数据中心的算力规模,以小鹏“扶摇”智算中心为例,其算力规模达到 600PFLOPS,换算成A100芯片大约需要至少1000片。当然这个量级和大模型算力规模相比,仍是小巫见大巫,后者一般1-2万片A100起步,据报道年初字节跳动向英伟达下单了10亿美金合同用于采购10万片A100。

虽然手握钞票无法买到高性能GPU芯片确实令人憋屈。
但是好消息是,一方面智驾模型训练并没有大模型苛刻,训练参量规模小很多,所以算力不够时间来凑的策略尚还可行,或者采用更多的稍低一些的算力芯片组合的方式缓解算力焦虑,或者租借其他公有云服务来补充,总能找到灵活的backup方案。
另一方面智驾训练的核心难点在于 城市道路场景,尤其是城市NOA下的非结构化长尾场景催生了更大的算力需求。
有别于Tesla基于纯视觉路线的强数据驱动,国内绝大多数城市NOA选择搭载LiDAR,LiDAR作为3D高精度传感器,核心的优势是直接映射3D环境结构化信息和目标3D尺寸位置,为降低视觉等训练算力要求提供了潜在机会。
所以关于禁令对智驾云端数据中心的影响评估总结是: 有影响,但影响可控,可以通过调整建设策略、优化训练策略和采用差异化智驾技术路线抵消部分负面影响。

至于车载端ASIC AI芯片,目前并不在新禁令限制范围内。此类芯片算力相比GPGPU算力偏小,更侧重推理阶段。
虽然英伟达在综合实力上仍是行业龙头,但没有完全碾压,国内诸多等位替换的公司对其形成了较好牵制。
如 地平线J5也拿下了不少主流车型订单,虽然算力有一定差距,但并不是代差,加上主机厂对域控平台的选择不仅看算力,还看工具链生态、算法支持和本土客户服务,这一点对于时间计划非常敏感的车型开发异常重要,此外算力差距还可以靠增加SOC芯片数量或优化算法功能来间接弥补。
幸运的是,目前最大的智驾域控芯片需求市场正是中国,英伟达车载边缘ASIC芯片绝大部分都卖给了中国公司。基于以往的经验,一旦中国占据绝对市场地位,奉行现实主义路线的美国是不敢轻易发布此类禁令的。
此外,考虑到智能驾驶功能从属于车整体,地位目前不及三电,尚未到靠智能驾驶能力争夺全球市场的阶段,所以车载ASIC AI芯片还没有进入到美国的视野,如果未来有一天智驾成为乘用车的核心竞争力和绝对卖点,而届时美国企业在核心产业链上有绝对的优势,不排除会有相关的禁令发布(禁令的前提是美国企业在产业链核心环节掌握绝对优势,否则像中国新能源三电系统这样的赛道早就被美国盯上了)。
但是汽车整车制造天然厌恶供应链风险,因为整车因供应链问题导致无法下线,损失是以分钟计,这是无法承受之重,比智算中心缺芯的后果要严重得多。所以一旦存在供应不确定性,必然会提前采取保供策略(缺芯导致),疫情期间缺芯的惨痛教训还历历在目。在多轮芯片禁令的影响下,敏感且老辣的主机厂肯定会做两手准备,积极寻找国产替代,其实很多主机厂在域控芯片的选择上已经考虑多种路线并行, 国外+国产双备份。
例如比亚迪新一代王朝和海洋系列的部分车型以及仰望U8选择搭载Orin X计算平台,而新发布的海狮将会搭载J5计算平台。
理想L9/L8/L7的AD Max是基于Orin X开发,而L8/L7的AD Pro均基于J5。
比亚迪和理想的双域控平台战略应该不是简单基于芯片功能参数的商业选择,大概率还有基于供应链风险管控的深层考量。
更有甚者当属蔚来,NT2.0车型全系智驾平台均选择Orin X独供,但其实早在2020年就悄悄组建了芯片团队自研域控算力芯片,重金投入,进展不俗。
五、禁令风险以后会不会继续扩大?
目前来看是极有可能的,这很大程度上取决于 中美两国通用AI大模型的发展速度。
如果中国的发展速度并没有得到预期的延缓,美国可能会出台进一步的限制措施,比如直接切断美国公司的GPU供货,甚至要求台积电停止面向中国公司的代工服务、禁止向中国公司授权ARM架构等等,极有可能让国产GPU公司停摆,彻底阻止中国公司获得高性能计算芯片。
另外随着智能驾驶渗透率不断提升和显性化价值持续增强,也会影响美国对该领域战略地位的观点和判断,以决定是否加强遏制。
果真如此,无异于脱钩断链,意味着中美的全面摊牌,近期中国对镓锗实施出口管制让全球半导体产业链为之震动,这正是对美国系列禁令的强硬反击,相信务实的美国在下一步行动上定会异常谨慎抉择。
除了对某类行业的制裁外,美国还会对单个中国公司进行精准打击,比如大疆、华为、中芯国际等。
当某个中国公司已经威胁了美国的科技和市场战略地位时,美国会毫不犹豫进行封杀,近年来屡试不爽。
未来一段时间达摩克里斯之剑会一直悬在中国AI芯片产业头上,打铁还需自身硬,唯有掌握核心能力才能行稳致远。




















