
智驾芯片五强,卡位下一个爆款



DeepSeek 往 AI 行业丢掷了一枚重磅炸弹。
低成本、低算力,做出了媲美 Chatgpt 的高性能模型。这项革新的直接影响者是英伟达,市值一度蒸发超 3000 亿美元。
这也使得关于「算力过剩」的讨论再度被拎上台面。
实际上,DeepSeek 的案例揭示了 AI 行业隐藏在算力神话下,更具含金量的东西,比如算法模型、芯片性能以及性价比。
它揭示了一个基本事实,算力只是关乎模型训练的有力条件,但不是充要条件。
今天留在牌桌上的芯片企业,英伟达、地平线、黑芝麻、华为、Mobileye 已经注意到了这点,从它们最新动作中可见,算力只是握在手中的筹码之一,且态度各异。
包括一度用算力标榜自身的英伟达,在当下也感到了不小危机感。
市场对于芯片企业的要求一直是做到未雨绸缪,现在它们都朝着软硬一体的大方向强化竞争壁垒,这其中,性价比才是重点,扩大生态圈才是核心。
01、算力斗兽场,上演「红与黑」
2022 年,英伟达发布了一颗算力猛兽——Drive Thor,AI 算力最高达到 2000TOPS,是上一代 Orin X(256TOPS)的 8 倍。
在业界还习惯于用 100TOPS 作为中、高算力的分水岭时,Thor 无疑来到了夸张级别。
但本应在 2024 年中量产的 Thor 陷入难产,最新消息是,Thor 的算力被修改为 1000TOPS,今年中将先提供 730TOPS 的低算力版本芯片。
把算力拉满,Thor 的确值得期待。
极氪、理想、小鹏、比亚迪、沃尔沃、丰田等车企,以及元戎启行、卓驭科技等供应商,早早就下了量产订单。
根本原因为,行业新技术对于算力的需求值涨到了千 TOPS 级别。
显著代表是「VLA」——视觉语言动作模型,被元戎启行、理想都视为开启端到端 2.0 时代的钥匙。但 VLA 需要处理大量视觉、语言等多模态数据,对于算力的需求更为苛刻。
目前,理想单「端到端+VLM」双系统模型,就需要消耗两颗 Orin-X 芯片,即 508TOPS 算力。
有行业人士认为,如果要部署「端到端+VLA」模型,Orin-X 显然不够,Thor 可能成为了必选项。
英伟达的 Thor 撕开了市场对于芯片超高性能的需求裂口,揭开整个算力市场「红与黑」的两面性。
红指激进。
在大算力纬度上,Thor 已经有了对手。
黑芝麻 2024 年 12 月底发布的华山 A2000 系列。

上一代 A1000 系列中的旗舰款,A1000Pro 的 AI 算力还是 106TOPS。
而新发布的 A2000Pro 尽管未直接标明算力大小,但从「4 倍行业旗舰芯片」的性能注解,可以预估至少有几百 TOPS,如果行业旗舰芯片指 Orin-X,那么 A2000Pro 的算力将来到 1000TOPS,与 Thor 不相上下。
地平线则在 2024 年 4 月推出征程 6 系列,覆盖低中高阶智驾,其中旗舰款产品征程 6P 的 AI 算力一度被拉到 560TOPS,几乎是征程 5(128TOPS)的 5 倍,Orin-x 的两倍。

据地平线介绍,征程 6P 采用「神经网络+规则引擎」的混合架构,支持端到端大模型,以及时下流行的 VLM、VLA 等技术路径。
值得一提的是,地平线征程 6P 的 560TOPS 算力旁,还有一句注解:在 1/2 稀疏网络下的等效算力。
它指的是征程 6P 在稀疏网络下 AI 算力可以达到 560TOPS。
所谓稀疏网络,是指网络中的权重矩阵中有大量的零权重,即只有部分神经元与前一层的神经元相连。
它对应的是稠密网络,指网络中的每个神经元都与前一层的每个神经元相连,没有零权重。
两者呈现的算力数值代表意义不同,可以简单理解为,稀疏算力指计算简单题的能力,而稠密算力指计算复杂题的能力。
目前包括英伟达,大多数芯片的高 TOPS 背后,其实指代的只是稀疏算力,相比稠密算力,它在数值表现上往往会高出一倍。
在这种情况下,华为选择强调稠密算力,由此引出了算力场「黑」的一面,即对算力保持克制态度。
华为昇腾 610 发布于 2020 年,算力 200TOPS,此后很长一段时间,华为暂未有发布新产品的正式动作。
原因有两点。
一是晟腾 610 足够能打,200TOPS 级别算力,已经是地平线 J5、黑芝麻 A1000Pro 的两倍,毫无疑问是算力王者。
更何况,200TOPS 是稠密算力,这意味着该芯片在处理智驾这类复杂计算任务时,效率更高,性能表现更好。
二是华为作为 Tier1 的身份,使其芯片可以在软硬一体的优势下,与算法协同发挥出更强大效能。
由此,伴随着华为乾崑 ADS 方案,昇腾 610 一直在市场吃香,据盖世汽车研究院数据显示,2024 年前 8 个月,华为昇腾 610 凭借 10.3% 的市占率在国内智驾域控芯片市场排名第三。
目前,华为对于昇腾 610 的预期已经提升至 L3 级,比如昊铂 GT 智驾版就搭载了昇腾 610,目前其同款硬件车型已经拿下了 L3 级的上路牌照。
如果说华为对于算力的克制是因为是提前冲刺,并且准备充分,Mobileye 就是一直小步慢跑,算力一点点往上加。
2022 年,Mobileye 发布的 EyeQ 6 系列芯片,AI 算力虽然是 EyeQ 5 的两倍,也仅为 34TOPS。
但 Mobileye 一直自信认为,EyeQ 6 High 的支持上限并不低,比如基于复合人工智能系统,搭载了 2 颗 EyeQ 6 High 的 SuperVision 方案能够达到可脱手的智驾能力。

而下一站的 EyeQ 7 系列,算力也仅是在 EyeQ 6 High 上继续翻倍,AI 算力仅为 67TOPS,不过制程突破到了 5nm,预计 2025 年中提供样品,在 2027 年开始量产。
与华为一样,Mobileye 的芯片与方案往往打包出售,并且,它认为大算力并不能决定一切。
Mobileye 认为 FPS 才是算力更贴切的指标,相比 TOPS 只计算每秒运算次数,FPS 计算每秒帧数的方式,更能直观体现该芯片在处理智驾图像、视频数据的能力。
比如 EyeQ6 High 每秒可以处理超过 1000 帧像素标记神经网络,相比 EyeQ5 的每秒 91 帧,效率提高了超十倍。
这意味着,EyeQ6 High 能够以高帧率完成图像数据处理,在感知、决策端拥有更好表现。
从理性主义出发,Mobileye 已经归纳出一条低成本、高性能抵达全无人驾驶的路径。尽管算力还未超过 100TOPS,但依托于对算法与规则的融合处理,它坚信这是一条可行的方法论。
02、软硬一体,性价比才是好生意
正如 Mobileye 所言,算力仅是芯片的核心评判维度之一。
今天关于芯片的终极讨论在于性能,芯片企业都瞄准了不同的价格带,竭力思考如何把性能拉到最满。
通过性价比超车,永远是一个更切实的机会。
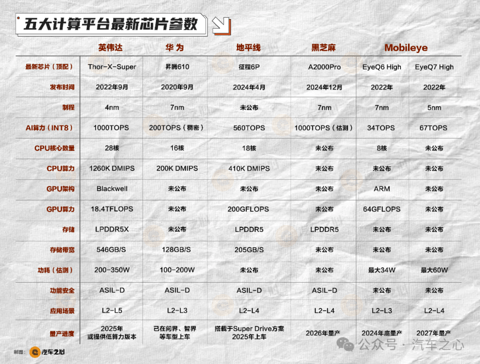
从目前各家芯片的特点中,其实能看到一些共性:
车规级芯片,获得 ASIL-D 安全认证;
集合 CPU、GPU、MCU 等多类型计算单元,完成异构计算;
7nm 制程成为最低门槛。
而当共识成为同质化表现后,芯片企业还需要面向未来,注入其它维度的「加成」打造差异化性能。
这里存在两个发力方向。
一是芯片都在围绕高效,强调「原生适配 Transformer 架构」。
这点像是在异构计算的基础上把力打透,Transformer 架构作为目前智驾行业公认的算法框架,芯片支持该模型,强调的是与主流算法适配,开发出高阶端到端智驾方案的能力。
此前 Orin-X 就因不支持 Transformer 架构,推理时延长,被理想诟病过。
所以英伟达在 Thor 的产品简介中,强调了其 CPU 采用了全新 Blackwell 架构,专为 Transformer 大模型和生成式 AI 功能设计的能力。
而地平线征程 6P 与黑芝麻 A2000Pro 也是在这点上「炫技」。
征程 6P 搭载了地平线自研的第三代 BPU 纳什架构,这种架构的特点在于灵活计算,即能够对 Transformer 算法中的各种细小操作进行高效处理,如目标检测、轨迹预测、路径规划等。
它能确保在处理复杂运算任务时,提供足够的精度与计算速度,同时三层存储架构的设计也能优化带宽。
黑芝麻 A2000Pro 同样应用了其独创的 NPU 架构——九韶,特点在于大核架构,解决了算力利用率低、延时高的问题,确保在面对复杂运算时能高效运行并输出准确推理结果。
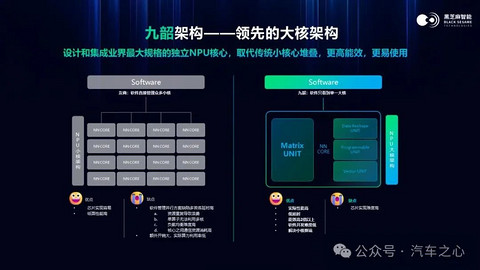
此外,芯片还集成了 Transformer 的硬加速模块,可以提升该模型的算法运行效率,并同样用三层内存架构降低了对外部存储的依赖。
思路其实是一致的,相当于此前是培训做题方法,现在是培训专有题型,把智驾难题做得更得心应手了。
二是优化服务能力,提供完整的开发工具链。
芯片公司如今卷起了软硬协同下的服务能力,这同样是「性价比」的重要表现。
一方面是开放,为开发者提供更多的自主性与可操作性。
Mobileye 从 EyeQ5 开始也意识到这点,芯片开始可编程操作。从 EyeQ6 系列开始,它开始提供软件开发工具包 EyeQ Kit,包含算法库、驱动程序等,能使得开发者基于需求完成个性化设计。
今年 CES 上,MobileyeCEO Amnon Shashua 教授还直言,「我们允许客户直接在芯片上托管第三方应用程序。」
当然,开放更是国内芯企的强项。
黑芝麻创始人单记章曾提到,黑芝麻芯片之上的每一层软件都可以进行定制与替换,进而拓宽使用场景,实现大规模出货。
这也来到开放的另一方面,提供更丰富、好用的开发工具。
比如,地平线、黑芝麻为了让开发者快速上手最新芯片,孵化了一整套开发工具,覆盖从标注、训练到仿真等模型开发全流程。
前者打造了 BPU 工具链、天工开物平台等。
后者则是构建了新一代 BaRT 工具链、双芯粒互联技术 BLink 等。
这些工具适配于 TensorFlow、PyTorch 等主流训练框架,可以帮助开发者充分利用芯片强大潜力,扩展算力边界,提高模型开发效率。
实际上,这些行为也在印证并加速软硬协同的大趋势。
黄仁勋一直把英伟达定位成软件与系统整合的企业,认为旗下的软件与硬件具备同等价值。

英伟达打造 Thor 能成为性能王者,离不开其在软件平台上的高速创新,这其中包括 CUDA 生态系统、Drive 软件平台、推理工具 TensorRT、数字孪生平台 NVIDIA Omniverse 等稳定的开发工具。
今天的芯片公司,不仅在比拼在底部构筑地基的能力,也在较量往高处建设大厦的水平。
03、生态攻防战,卡位下一个爆款
芯片企业已经告别了单纯卖硬件的生意模式。
它们构建完整开发工具链背后,是一直反复强调的关键词:生态。
比如英伟达,屹立不倒的重要原因之一,源于其早早就构建了一整套成熟的生态系统,让客户形成一定的技术依赖与转换成本,产生粘性。
而国内的后起之秀地平线、黑芝麻也通过性价比策略接连完成了从 0 到 1 的生态建设过程,并敲响上市钟声。
而华为、Mobileye 在生态建设上具有先天优势。
两者作为智驾供应商,能够通过出售软硬一体的方案增加芯片出货量。
华为的芯片,背靠鸿蒙智行、Hi 模式,享受着「朋友圈」不断扩大的销量红利;
Mobileye 芯片则依靠早期品牌声量积累,能够吃到全球化市场的蛋糕。
现在,五家芯片企业在不同节奏下走到了分岔路口。
在如何进一步上量,扩大生态圈的命题面前,选择了不同方向。
一是强调可扩展性,扩大生态横截面。
英伟达打了个样,Thor 的应用场景已经不止 L2、L3 阶段,它能够覆盖智驾全场景,包括 L4 的 Robotaxi,已经 L5 全无人驾驶阶段。

而黑芝麻也立刻跟上,其对于 A2000Pro 的定位是全场景通识智驾,简单理解就是强调芯片对于驾驶场景的全面理解能力,包括城市道路、高速公路、昼夜变化及各类天气条件下的不同场景。
这意味着,A2000Pro 同样可以覆盖从 L2-L5 的全场景智驾。
值得一提的是,黑芝麻智能 CMO 杨宇欣曾表示,A2000 将不止于智驾,还会面向具身智能等大模型应用场景去拓展。
他表示,机器人的产业链、生态的布局和结构跟汽车的重叠度非常高。
这指向了智驾芯片企业的另一条增长曲线。
二是深度强化软硬一体,从 Tier2 向前大迈步。
随着智驾开发周期越来越紧张,芯企需要灵活配合车企/方案商,满足不同的市场需求。
若车企/供应商有自研能力,则提供灵活性开发工具进行适配;
若没有模型开发经验,则提供全栈软件方案。
黑芝麻在 A2000 系列发布前不久推出了端到端算法参考方案,基于端到端架构,在决策单元引入了 VLM 视觉语言模型与 PRR 行车规则等,提升智驾系统决策规划能力。
这相当于一个智驾 Demo,帮助车企/供应商快速上手软件开发。
值得一提的是,地平线在战略上选择了 All in。
从纵向、横向把市场全面吃透。
凭借 700 万颗芯片出货量成绩,地平线已经牢牢稳住了国内低阶、高阶市场位置,分别仅次于 Mobileye 与英伟达。
而从征程 6 系列开始,地平线依然可以用「芯片全家桶」的形式,吃准低中高阶智驾的新需求。
此外,地平线也在延展商业边界,用征程 6P 打出了 SuperDrive 这张王牌,该方案目前已经在北京晚高峰、上海老城区等复杂场景中进行测试,做到了全程无接管,今年 8 月实现量产落地。
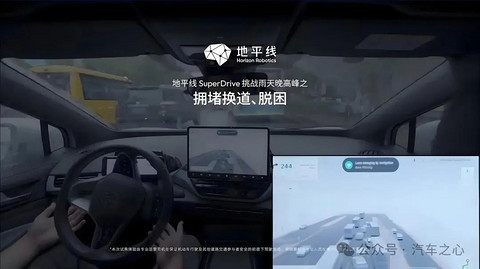
从芯片到完整方案,地平线重新定义了自我身份,将商业生态的天花板继续抬高。
由此,一轮新的较量在芯片行业开始上演,在这个同样研发投入巨大,靠高出货量解渴的供应链上,各家都加紧扩建森林,打造良性循环的生态模式。
更残酷的一点是,身处 AI 急剧变化的时代,一条游戏规则改写就足以颠覆整个行业。
DeepSeek 已经敲响了警钟,今天的芯片企业必须时刻紧绷着,它们不仅要炼出锋利的武器攻擂,还要磨出坚固的盾牌守塔。
在攻防之间,芯片企业们,亟待下一个爆款出现。




















